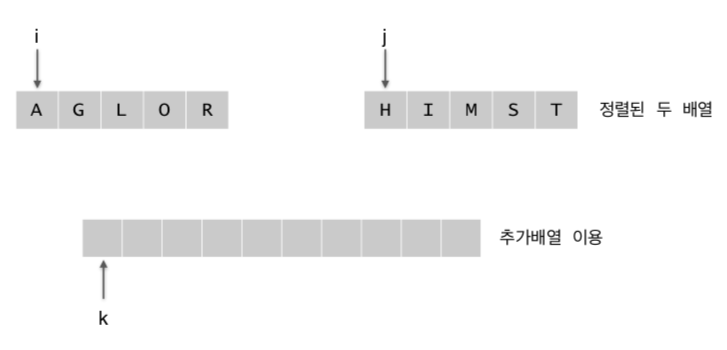
- i(첫번째 list에서 가장 작은 값), j(두번째 list에서 가장 작은 값), k(추가 list에서 가장 작은 값) 변수 필요
1. A[i]와 A[j]를 비교하여 작은 값을 추가 배열에 추가
2. 작은 값에 속한 인덱스 올림. i++ or j++ , k++
3. i or j가 해당 배열의 인덱스보다 크다면 다른 배열의 값은 그대로 추가배열에 추가 해주면 됨!
소스
// 재귀 함수이므로 매개변수 명시화 필요
public void mergeSort(int[] arr, int p, int r) {
if (p < r) {
int q = (p+r) / 2; // 1. p와 r의 중간 지점 계산
mergeSort(arr, p, q); // 2. 전반부 정렬
mergeSort(arr, q+1, r); // 3. 후반부 정렬
merge(arr, p, q, r); // 4. 합병
}
}
/* Merge Business Logic - 정렬되어 있는 두 배열 arr[p...q]와 arr[q+1...r]을 합하여
* 정렬된 하나의 배열 arr[p...r]을 만듦.
* arr[p... q] arr[q+1...r] => 정렬되어 있는 두 배열
* arr[p.................r] => 정렬된 하나의 배열을 만드는 작업 : Merge
*/
public void merge(int[] arr, int p, int q, int r) {
int i=p, j=q+1, k=p;
int[] temp = new int[arr.length];
// 각각 i, j가 각 배열의 길이를 넘지 않는다면 비교하여 temp에 넣어주기
while(i <= q && j <= r) {
if (arr[i] <= arr[j]) {
temp[k++] = arr[i++];
} else {
temp[k++] = arr[j++];
}
}
// 첫번째 배열에 있는 나머지 값들은 이미 정렬된 데이터들이므로 차례대로 temp 배열에 넣어주면 됨.
while (i <= q) {
temp[k++] = arr[i++];
}
// 두번째 배열에 있는 나머지 값들은 이미 정렬된 데이터들이므로 차례대로 temp 배열에 넣어주면 됨.
while(j <= r) {
temp[k++] = arr[j++];
}
// index p부터 r까지 원래 배열에 값 넣기
for (int l = p; l <= r; l++) {
arr[l] = temp[l];
}
print(arr);
}
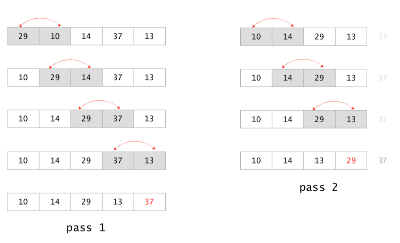
public void selectionSort(int[] arr) {
if (arr.length == 0 ) {
return;
}
System.out.print("[정렬할 원소] ");
print(arr);
int max;
for (int last = arr.length-1; last>0; last--) { // 1
max = last - 1;
// 마지막을 제외한 나머지 element 중 가장 큰 수 찾기
for (int k = last-1; k >= 0; k--) { // 2
if (arr[k] > arr[max]) {
max = k;
}
}
if (arr[max] > arr[last] ) {
swap(arr, max, last); // 3
}
System.out.print(arr.length - last + "단계 : ");
print(arr);
}
}
실행 시간
1번의 for 루프 n-1 번 반복
2번에서 가장 큰 수를 찾기 위한 비교 횟수: n-1, n-2, ..., 2, 1
3번의 교환은 상수시간 작업
시간 복잡도: T(n) = (n-1)+(n-2)+...+2+1 = n(n-1)/2 = O(n^2)
API (Application Programming Interface) - 개발자가 공개적으로 노출한 멤버들을 사용하여 기능에 접근하고, 해당 기능을 구현하는데 사용된 코드를 숨길 수있는 인터페이스
SDK(System Development Kit) - 소프트웨어 개발 도구 모음 - SDK 안에는 개발에 도움이 될 개발 도구 프로그램, 디버깅 프로그램, 문서, API 등이 있다.
Software Framework - 정의된 API를 제공하는 Software library의 모음 - 라이브러리와 달리 애플리케이션의 틀과 구조를 결정할 뿐만 아니라, 그 위에 개발된 개발자의 코드를 제어함.
Software Library - 컴퓨터 프로그램에서 자주 사용되는 부분 프로그램들을 모아 놓은 것. - 정적, 동적(링크, 로드) 라이브러리로 나뉨
2. Framework vs. Library 심층 분석
결론: 누가 누구를 호출하느냐의 차이 (who calls who)
프레임워크에서는 프레임워크 코드가 우리 코드를 호출하고, 라이브러리에서는 우리 코드가 라이브러리를 호출한다.
Inversion of Control (IOC) JavaScript 프레임워크인 jquery를 예로, Document가 준비 상태(document on ready)일 때 우리가 정의했던 콜백을 호출하는 것은 프레임워크이다. 이것은 프레임워크가 담당하는 프레임워크의 통제부분의 흐름이다.
Framework code: 통제 흐름을 정의 Your code: 행동을 정의 Library code: 행동을 정의
프레임워크와 라이브러리의 차이점은 Control에 관한 것. 통제의 흐름(flow of control)이 그 차이이다. 프레임워크는 당신의 애플리케이션의 흐름을 통제하고, 라이브러리는 그러지 않는다.
Reference. https://www.youtube.com/watch?v=D_MO9vIRBcA http://waaan.tistory.com/15
멀티 프로세스와 멀티 스레드는 '동시에두가지이상의루틴을실행할수있는역할'을 하는 것은 동일하다.
그럼 어떠한 차이점이 있을까?
멀티 프로세스(Multi Process)
부모-자식 관계라고 해도 자신만의 메모리 영역을 가지게 된다.
환경변수와 프로세스 핸들 테이블이 상속 가능할 뿐 결국 독립적인 관계이다.
fork를 통해 프로세스를 복사한다.
유닉스 계열에서 ps 명령어로 현재 수행되고 있는 프로세스를 확인할 수 있다.
프로세스 간의 통신을 하려면 IPC(Inter Process Communication; 세마포어, 큐, 공유메모리)를 통해야 한다.
멀티 스레드(Multi Thread)
하나의 프로세스가 다수 개의 작업을 각각 스레드를 이용하여 동시에 작동 시킬 수 있다.
스레드는 다음과 같은 공유 메모리를 가진다.
프로그램이 동작하기 위해서는 두가지의 메모리 공간이 필요하게 된다.
코드 공간 : 특정 프로세스의 동작상태를 기록하는 것으로 하나의 프로세스가 독립적인 코드 포인터를 가지고 동작하기 위해 필요하다.
데이터 공간 : 하나의 프로세스가 작동 중에 필요로 하는 데이터를 저장해 두기 위한 것으로 프로그램 변수나 메모리 스택 공간을 말한다.
멀티 스레드는 멀티 프로세스에 비해 상당한 이점을 가진다
컨텍스트 스위칭(Context Switching) 시에 공유 메모리 만큼의 시간(자원) 손실이 줄어든다. : 프로세스 간의 컨텍스트 스위칭시 단순히 CPU 레지스터 교체 뿐만이 아니라 RAM과 CPU사이의 캐쉬메모리에 대한 데이터 까지 초기화 되므로 상당한 부담이 발생한다.
Stack을 제외한 모든 메모리를 공유하기 때문에 global(전역), static(정적) 변수 그리고 new, malloc에 의한 모든 자료를 공유할 수가 있다. : 이는 프로세스간 통신(ex.pipe)과 같이 복잡한 과정을 거치지 않고 보다 효율적인 일처리가 가능하다는 것을 뜻한다. (핸들 테이블과 환경변수는 덤이다.)
결국 계산기와 메모장 처럼 서로 완전히 별개의 프로그램이라면
독립적은 프로세스를 구성해야겠지만 서로 관련된 기능들은 멀티 스레드로 구현하는 것이 이득이다!
멀티 스레드의 효율성과 안정성 문제
여러 개의 스레드가 동일한 데이터 공간을 공유하면서 이들을 수정한다는 점에 필연적으로 생기는 문제이다.
멀티 프로세스의 방식의 프로그램에서 하나의 프로세스가 자신의 데이터 공간을 망가뜨린다면 그것은 해당 프로세스의 중단을 낳게 될 것이다. 하지만 멀티 스레드 방식의 프로그램에서는 하나의 스레드가 자신이 사용하던 데이터 공간을 망가뜨린다면 그 결과는 하나의 데이터 공간을 공유하는 모든 스레드를 작동불능 상태로 만들어 버릴 것이다. 이러한 문제에 대비하기 위해 Critical Section 기법이 존재한다.